
This Guide is Outdated!
The updated guide can be found here
A Complete Guide to Speech Emotion Recognition in Tensorflow Using CNNs and CRNNs
Speech Emotion Recognition (SER) involves analyzing various acoustic features of speech signals to identify emotional states. These features include pitch, volume, tempo, and pauses in speech. Machine learning algorithms are trained on labeled datasets containing audio recordings with corresponding emotion labels (e.g., happy, sad, angry). The models then learn patterns that correlate these acoustic features with specific emotions.
There are two primary approaches to Speech Emotion Recognition:
- Rule-based systems: These systems rely on predefined rules and heuristics to map acoustic features to emotional states. For example, a high pitch might be associated with happiness while a low pitch could indicate sadness. However, these systems may struggle in cases where emotions are not clearly expressed through typical vocal patterns or when multiple emotions are present simultaneously.
- Data-driven models: These models use machine learning algorithms to learn relationships between acoustic features and emotional states from labeled datasets. Data-driven approaches tend to be more accurate than rule-based systems but require large amounts of high-quality training data. Deep neural networks, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN), are commonly used in this context.
We will be using the second approach in this project due to its flexibility and superior performance.
We will be using four datasets in this project:
We will also be using three different models to classify emotions:
- A Convolutional Neural Network (CNN) trained on the Mel Spectrograms of the audio files.
- A CNN trained on the Mel Frequency Cepstral Coefficients (MFCCs) of the audio files.
- A Convolutional Recurrent Neural Network (CRNN) trained on the Mel Frequency Cepstral Coefficients of the audio files.
1. Data Collection
We will be using the Kaggle API to automate the process of downloading the datasets. The datasets will each be unzipped to a separate folder.
# Collect CREMA-D audio dataset from Kaggle into a folder called 'cremad'
!kaggle datasets download -d ejlok1/cremad --unzip -p cremad# Collect RAVDESS audio dataset from Kaggle into a folder called 'ravdess'
!kaggle datasets download -d uwrfkaggler/ravdess-emotional-speech-audio --unzip -p ravdess# Collect TESS audio dataset from Kaggle
!kaggle datasets download -d ejlok1/toronto-emotional-speech-set-tess --unzip# Collect SAVEE audio dataset from Kaggle into a folder called 'savee'
!kaggle datasets download -d ejlok1/surrey-audiovisual-expressed-emotion-savee --unzip -p savee2. Data Wrangling
Each of the datasets has a different way of naming the audio files and their labels. Each dataset also has different emotions. So, we will have to do some wrangling to get them all in the same format.
# Import necessary libraries
import os
import pandas as pd
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
# This allows normalization for the specgrams which allows for clearer visualizations
from matplotlib.colors import Normalize
import seaborn as sns
import tensorflow as tf
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings('ignore')
# Set style and color palette
sns.set_theme(style='darkgrid', palette='magma')
# Change the setting and put it in a dictionary
plot_settings = {
'font.family': 'calibri',
'axes.titlesize': 18,
'axes.labelsize': 14,
'figure.dpi': 140,
'axes.titlepad': 15,
'axes.labelpad': 15,
'figure.titlesize': 24,
'figure.titleweight': 'bold',
}
# Use the dictionary variable to update the settings using matplotlib
plt.rcParams.update(plot_settings)Let’s wrangle the datasets into a useable format.
# Put the cremad directory in a list
cremad = os.listdir('cremad/AudioWAV/')
# Make a list for emotion labels and a list for path to audio files
emotions = []
paths = []
# Loop through all the files and extract the emotion label and path
for file in cremad:
# Extract the emotion label from the file name
emotion = file.split('_')[2]
if emotion == 'SAD':
emotion = 'sadness'
elif emotion == 'ANG':
emotion = 'anger'
elif emotion == 'DIS':
emotion = 'disgust'
elif emotion == 'FEA':
emotion = 'fear'
elif emotion == 'HAP':
emotion = 'happiness'
elif emotion == 'NEU':
emotion = 'neutral'
elif emotion == 'SUR':
emotion = 'surprise'
else:
emotion = 'Unknown'
# Extract the path
path = 'cremad/AudioWAV/' + file
# Append the emotion and path to their lists
emotions.append(emotion)
paths.append(path)
# Create a dataframe from the lists
cremad_df = pd.DataFrame(emotions, columns=['Emotion'])
cremad_df['Path'] = paths
# Inspect the dataframe
cremad_df.head()
We use a similar process for each dataframe. All the dataframes should look similar, each row having an emotion and a path.
3. Data Exploration, Preparation, and Visualization
Plotting the histograms of the dataframes gives us these counts:

These are the counts for each emotion:

In total, we have 12,162 audio files. The complete dataset is adequately balanced except for the calm, surprise, and neutral emotions. As for the calm emotion, it is extremely similar to the neutral emotion, so we will drop it.
Neutral is similar in count to the other emotions, so we will keep it. Surprise would be the only unbalanced emotion, but we will keep it as well, as it is an important emotion to recognize.
Next, we need to load the audio files, we will be using a library called librosa. We will be using the load function, which loads audio data from various formats such as WAV, MP3, AIFF, etc., into Python for analysis and manipulation. The librosa library is widely used in the field of audio signal processing due to its efficiency and user-friendly interface.
# Get a sample from each emotion type
sample = df.groupby('Emotion', group_keys=False).apply(lambda x: x.sample(1))
# extract the path from the sample
sample_paths = sample['Path'].tolist()
# Create a waveform plot for a sample of each emotion
plt.figure(figsize=(14, 10))
for i in range(7):
plt.subplot(4, 2, i+1)
# Load the audio file and set the sampling rate to 44100
data, sr = librosa.load(sample_paths[i], sr = 44100)
# Plot the waveform
librosa.display.waveshow(data, sr=sr)
# Add a title
plt.title(sample['Emotion'].values[i], fontweight='bold')
# Add labels to the x and y axes
plt.ylabel('Amplitude')
plt.xlabel('Time (seconds)')
# Adjust the layout so there are no overlapping titles
plt.tight_layout(pad=2)
This shows the waveforms of the audio files, which gives us a visual representation of how the sound pressure varies over time in each audio file. Waveform plots are useful to understand some basic characteristics of an audio signal such as its duration, amplitude envelope (i.e., loudness variation over time), and any discernible patterns or features that might be indicative of specific sounds or speech segments.
However, waveforms alone may not capture the full spectrum of frequencies present in a sound at each moment in time. This is where Mel Spectrograms come into play. While waveform plots provide information about how loudness changes over time, Mel Spectrograms offer insights into how different frequency components change over time and contribute to the overall audio signal.
In other words, while waveforms are helpful for understanding basic properties of an audio file like its duration or general amplitude pattern, Mel Spectrograms provide a more detailed view of the sound’s composition in terms of both temporal dynamics (how it changes over time) and spectral content (which frequencies are present at each moment). This makes them particularly useful when training machine learning models for tasks such as speech recognition or audio classification.
This is what a mel spectrogram looks like:

In simpler terms, a Mel Spectrogram is like a colorful map that shows how sounds change over time. It’s particularly useful for speech recognition because it captures both the frequency and intensity of sound waves in a way that mimics how our ears perceive them.
To create a Mel Spectrogram, we first break down an audio signal into smaller chunks called windows. We then apply a mathematical technique known as the Short Time Fourier Transform (STFT) to each window. This transforms the time-domain signal into its frequency domain representation. The result is a matrix of complex numbers that represent the frequencies present in each window at different times.
Next, we convert these frequencies from their original scale (linear frequency) to what’s called the ‘mel’ scale. The mel scale is designed to mimic how our ears perceive pitch, which is logarithmic, in “decibels”, rather than linear. This means that small changes in frequency correspond to larger perceived differences in pitch as you move up the scale.
Finally, we map the power of these frequencies (i.e., their loudness) onto a color spectrum, with brighter colors representing louder sounds. The resulting image is our Mel Spectrogram – a visual representation of how the sound waves change over time in terms of both frequency and intensity.
Let’s look at a sample of each emotion as mel spectrogram:

As we can see, each emotion looks a bit different from the others. This can give you an idea of how the model can predict the emotion from the Mel Spectrogram.
4. Data Preprocessing
We will create a function that takes an audio file path and returns the mel spectrogram as an image in the form of a numpy array. This allows us to use the image arrays immediately as inputs.
# Create a function that takes an audio file path and returns the mel spectrogram
# as an image, and converts the image into a numpy array
def process_audio(path):
'''
Load the audio file, convert the audio file into a mel spectrogram,
return the mel spectrogram as an image, and convert the image into a numpy array
'''
# Load the audio file and set the sampling rate to 44100
audio, sr = librosa.load(path, sr=44100, duration=4, mono=True)
# pad the audio files that are less than 4 seconds with zeros at the end
if len(audio) < 4 * sr:
audio = np.pad(audio, pad_width=(0, 4 * sr - len(audio)), mode='constant')
# Convert the audio file into a mel spectrogram
signal = librosa.feature.melspectrogram(y = audio, sr=sr, n_mels=128)
# Convert the spectrogram from amplitude squared to decibels
# as amplitude does not give us much information
signal = librosa.power_to_db(signal, ref=np.min) # Convert the image into a numpy array
image = np.array(signal)
# Return the image
return imageWe pad the audio files with zeros and truncate the extra seconds so that each file is 4 seconds before converting them into mel spectrograms. This is so that each audio file has the shape before inputting it into the CNN.
The parameters of the melspectrogram are as follows:
y (audio signal):This is your input audio data, which can be either a single value or an array of values representing the sound pressure level over time. It should have the same shape as the output of `librosa.load()` without the sampling rate.sr (sampling rate):The sampling rate at which the audio signal was recorded. This is necessary for correctly applying the Short Time Fourier Transform (STFT) and calculating frequencies accurately. It should match the second return value of `librosa.load()`.n_mels (int, optional):Number of Mel frequency bins. Defaults to 64 if not specified. This determines how many different frequency bands you want your spectrogram to represent. More mel bins will result in a more detailed spectral representation but also increase the dimensionality of your data.hop_length (int, optional):Number of samples between Mel Spectrogram frames. Defaults to 256 if not specified. This determines how much time passes between each frame or “snapshot” of the spectrogram. Smaller values will result in more detailed temporal information but also increase the total number of frames and computational cost.n_fft (int, optional):Number of samples used for Fourier transform. Defaults to 2048 if not specified. This determines how many samples are used at once when calculating the STFT. Larger values will result in a more detailed frequency representation but also increase computational cost and memory usage.
We then divide the data into features and labels and split them into training and testing sets, with a 80:20 split.
# Divide the data into features and labels
X_mel = [process_audio(path) for path in df['Path']]
y_mel = df['Emotion']
# Divide the data into training and testing sets, with a 80:20 split
X_train_1, X_test_1, y_train_1, y_test_1 = train_test_split(X_mel, y_mel,
test_size=0.2,
random_state=0,
shuffle=True)The training and testing sets should have the following shapes:

Where the first value is the number of images, the second is the n_mels value, or the number of bins, and the third is the number of “frames”, where each frame is a segment or portion of an audio signal that is analyzed separately for feature extraction purposes.
We then standardize the data by making the mean 0 and standard deviation 1 before feeding it into the model, this is a common preprocessing step to ensure that all input features have similar scales and are expressed in terms of their distance from the mean (zero) and spread (standard deviation). Standardizing the data can lead to several benefits:
- Feature Importance Balancing: Standardization ensures that all features contribute equally in terms of their distance from the mean (0) and spread (standard deviation). This prevents certain time frames or frequency bins with larger magnitudes or ranges from dominating the model’s learning process, as they would otherwise have a stronger influence on the loss function due to their scale.
- Invariant Representation Learning: Standardization helps CNN models learn representations that are invariant to the overall magnitude and range of the input features. This can lead to more robust feature extraction and better generalization capabilities when dealing with new, unseen data.
- Efficient Feature Extraction: By standardizing the Mel Spectrogram data, you ensure that CNNs can effectively compare and extract relevant patterns across different time frames or frequency bins. This is because all features are expressed in terms of their distance from the mean (0) and spread (standard deviation), making it easier for the model to learn meaningful representations.
- Improved Training Convergence: Standardizing the data can lead to faster convergence during training, as the learning process becomes less influenced by the scale or range of individual features. This results in a more efficient use of computational resources and potentially better overall performance.
# Standardize the data by subtracting the mean and dividing by the standard deviation
mean = np.mean(X_train_1)
std = np.std(X_train_1)
X_train_1 = (X_train_1 - mean) / std
X_test_1 = (X_test_1 - mean) / stdNext, we make a Dataset object from the data. This will allow us to make batches, and prefetch the data, which means that the data will be loaded to the GPU while the model is training on the previous batch. This will make the training process faster.
# Divide the data into batches of 32 images
batch_size = 32
# Make a training dataset from the training set
train_dataset_1 = tf.data.Dataset.from_tensor_slices((X_train_1, y_train_1))
# Shuffle, batch, and prefetch the data
train_dataset_1 = train_dataset_1.batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# Make a testing dataset from the testing set
test_dataset_1 = tf.data.Dataset.from_tensor_slices((X_test_1, y_test_1))
# Shuffle, batch, and prefetch the data
test_dataset_1 = test_dataset_1.batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)5. Modeling
5.1- Speech Emotion Recognition with CNN Model using Mel Spectrograms
By treating Mel Spectrograms as images and using Convolutional Neural Networks (CNN) for classification, you can leverage the power of deep learning models specifically designed to handle image data. The main benefits include:
- Feature Extraction: CNNs excel at extracting relevant features from images or 2D representations like Mel Spectrograms, learning meaningful representations directly from raw spectrogram data without extensive preprocessing or feature engineering.
- Invariance: By learning translational and other types of invariances during training, CNNs can make your model more robust to small variations in the input data such as changes in amplitude, noise, or slight shifts in frequency.
- Hierarchical Representation Learning: The convolutional layers in a CNN process input data at different levels of abstraction, allowing for hierarchical representation learning that captures both low and high-level information from Mel Spectrograms effectively.
- Transfer Learning: You can Leverage pre-trained CNN models trained on large image datasets like ImageNet as a starting point and fine-tune them for your specific task of classifying Mel Spectrograms, utilizing their general feature extraction capabilities while adapting to your problem.
- Parallelization: Efficiently train CNNs using parallel computing architectures like GPUs or TPUs, enabling faster training times and processing larger datasets more quickly.
- Model Interpretability: The convolutional layers in a CNN produce feature maps that highlight important regions of the input, making it easier to understand what parts of the Mel Spectrogram are contributing to the classification decision.
- Robustness: CNNs are generally robust to slight variations or transformations in the input data (e.g., rotation, scaling), suitable for handling variability in Mel Spectrograms due to factors like recording conditions and individual differences.
- Speed: Once trained, a well-designed CNN can quickly classify new Mel Spectrograms, allowing for real-time or near-real-time processing of audio data.
We will be using this architecture:
# Define the CNN model
model_mel = tf.keras.Sequential([
# First convolutional layer
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(128, 345, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
# Batch normalization maintains the 0 mean and 1 standard deviation
tf.keras.layers.BatchNormalization(),
# Second convolutional layer
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Third convolutional layer
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Fourth convolutional layer
tf.keras.layers.Conv2D(256, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Global average pooling layer averages the values in each feature map into
# a single value and flattens the result into a (None, 256) array
tf.keras.layers.GlobalAveragePooling2D(),
# Dropout layer randomly sets 50% of the activations to zero
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(7, activation='softmax')
])The tf.keras.layers.GlobalAveragePooling2D() layer has several benefits over flattening and using Fully Connected layers, including:
- Reduced Number of Parameters: Global Average Pooling (GAP) significantly reduces the number of parameters in your model compared to fully connected (FC) layers. This leads to a smaller model size and fewer computations during training, which can speed up the overall process.
- Retains Important Information: By taking an average over each spatial dimension, GAP retains important information about the overall distribution of features in your input data while discarding noise and irrelevant details. This helps maintain model performance without increasing complexity.
- Simplified Architecture: Using GAP instead of flattening followed by FC layers simplifies your model’s architecture, making it easier to understand and interpret. It also reduces the risk of overfitting since there are fewer parameters in the network.
- Efficient Computation: Global Average Pooling requires less computation compared to flattening followed by FC layers because it directly operates on the spatial dimensions without needing to reshape or transpose the input data. This can lead to faster training and inference times, especially when working with large datasets.
- Compatibility with Convolutional Layers: GAP is well-suited for use after convolutional layers because it operates on the same spatial dimensions as convolutions (e.g., 2D images or Mel Spectrograms). This makes it a natural choice for building end-to-end trainable models that treat Mel Spectrograms as images and learn features directly from raw audio data.
- Retains Spatial Information: Unlike other pooling methods like max pooling, which only retain the most prominent feature in each spatial location, GAP retains information about all features across the entire input. This can be beneficial for tasks where contextual or relative information between different parts of the Mel Spectrogram is important.
- Improved Generalization: By taking an average over all spatial locations, GAP helps your model generalize better to new data by smoothing out fluctuations and reducing the impact of noisy or irrelevant features in the input data. This can lead to improved performance on unseen datasets.
This model plateaus after 40 epochs at 71% validation accuracy, with an F1-Score of 0.73. This is a great accuracy for such a complex task, as it is hard for even a human to recognize a very specific emotion from an audio file 2-4 seconds long, but we can do better.
5.2- Speech Emotion Recognition with CNN Model using MFCCs
MFCCs are a popular feature extraction technique in speech and audio processing tasks. MFCCs convert short-term power spectra of speech signals into a set of features that are more compact, robust to distortions, and easier for machine learning algorithms to process. They capture the frequency composition of an audio signal at different time instances while being invariant to certain transformations like pitch scaling or time stretching.
Using MFCCs in emotion recognition tasks can offer several benefits:
- Robust Feature Representation: MFCCs provide a more robust and compact representation of the audio signals, capturing essential acoustic characteristics that may be indicative of different emotions. This can lead to improved model performance compared to using raw waveform data or simple spectrogram representations.
- Dimensionality Reduction: By transforming high-dimensional spectrograms into a lower-dimensional feature space, MFCCs help reduce the dimensionality and complexity of the input data for our machine learning models. This can lead to faster training times, less overfitting, and easier interpretation of model results.
- Consistency Across Datasets: MFCCs provide a standardized way of representing audio signals, making it easier to compare and combine datasets from different sources or experiments. This can lead to more consistent results across studies and improve the generalizability of our models.
- Invariance to Certain Transformations: As mentioned earlier, MFCCs are invariant to certain transformations like pitch scaling or time stretching. This property makes them useful in emotion recognition tasks where variations in speech rate or pitch may be associated with different emotions but should not affect the underlying emotional content of the audio signal.
- Improved Performance in Speech Emotion Recognition Tasks: Numerous studies have shown that using MFCCs can lead to improved performance in various speech and audio classification tasks, including emotion recognition. By leveraging this proven technique, we can expect better results for our own emotion recognition model. This review explains MFCCs and its performance in many applications in more detail.
We will also treat the MFCCs as images and use a CNN to classify them. Let’s create a function that extracts MFCCs from an audio file:
# Create a function that extracts MFCCs from an audio file
def extract_mfcc(path):
'''
Load the audio file, convert the audio file into MFCCs and return the MFCCs
'''
# Load the audio file and set the sampling rate to 44100
audio, sr = librosa.load(path, sr=44100, duration=4, mono=True)
# Pad the audio files that are less than 4 seconds with zeros at the end
if len(audio) < 4 * sr:
audio = np.pad(audio, pad_width=(0, 4 * sr - len(audio)), mode='constant')
# Convert the audio file into MFCC
signal = librosa.feature.mfcc(y = audio, sr=sr, n_mfcc=128)
# Return the MFCCs as a numpy array
return np.array(signal)We usually normalize MFCCs because this improves the overall performance, stability, and robustness of our speech recognition system while simplifying hyperparameter tuning. This is how a normalized MFCCs spectrogram looks like.

As before, we apply the function to the dataset, split it into training and testing, and train a CNN model with the same architecture. After 31 epochs, the model plateaued around a validation accuracy of 74.2% and an F1 score of 0.76.
5.3- Speech Emotion Recognition with CRNN Model using MFCCs
Next, let’s build a CRNN model. A CRNN is a combination of a CNN and an RNN. The CNN is used to extract features from the input, and the RNN is used to model the temporal dependencies in the sequence of extracted features.
Convolutional Recurrent Neural Networks (CRNNs) are typically employed for tasks that involve processing sequential data with both spatial and temporal dependencies, such as speech recognition, audio classification, video analysis, and time series prediction. These applications require models capable of extracting meaningful features from the input data while also considering their temporal context.
We will be using this architecture:
# Build a CRNN model
model_crnn = tf.keras.Sequential([
# First convolutional layer
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(128, 345, 1), padding='same'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Second convolutional layer
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Third convolutional layer
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Fourth convolutional layer
tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
# Global average pooling layer averages the values in each feature map into
# a single value and flattens the result into a (none, 256) array
tf.keras.layers.GlobalAveragePooling2D(),
# Reshape layer to convert (none, 256) to (none, 1, 256) as the LSTM layer
# requires a 3D input
tf.keras.layers.Reshape((1, 128)),
# First bidirectional recurrent layer
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),
# Second bidirectional recurrent layer
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
# Dropout layer randomly sets 50% of the activations to zero
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(7, activation='softmax')
])The CRNN model plateaued around 73.3% accuracy and an F1 score of 0.75.
6- Evaluation and Conclusion

The MFCC CNN model outperformed both the Mel Spectrogram CNN and CRNN models. It achieved a validation accuracy of around 74.2%, which is a significant improvement over the Mel Spectrogram CNN’s 71% validation accuracy. This indicates that MFCCs can be better at representing audio files than Mel Spectrograms, leading to improved model performance.
The CRNN model had the second-best validation accuracy but suffered from overfitting. Despite its powerful capabilities, CRNN models can be prone to overfitting when working with smaller datasets or less informative input features like Mel Spectrograms. However, in scenarios where there is a strong temporal component and sufficient data, CRNNs can excel at capturing both spatial and temporal dependencies.
The Mel Spectrogram CNN model performed the worst among the three models but still achieved good validation accuracy (around 71%). It generalized well, with its training and validation accuracies being relatively close. This suggests that while Mel Spectrograms may not be as effective at representing audio files compared to MFCCs, they can still provide useful information when combined with a CNN architecture.
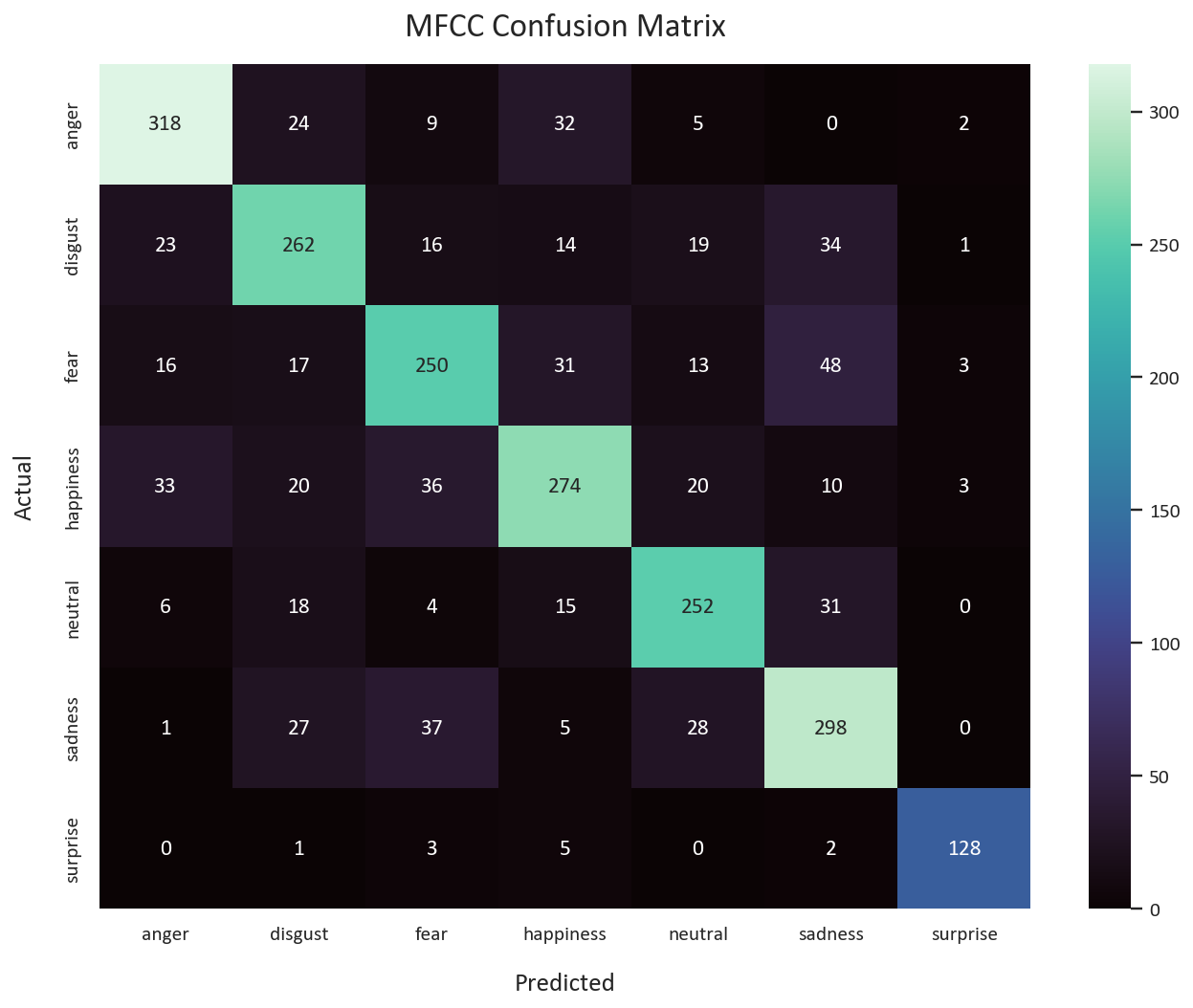
We can see that the models performed well in general, with fear and sadness being the least recognized emotions. This is expected, as fear and sadness are very subtle emotions, and they are hard to recognize even for humans.
As for the f1-scores, the MFCC CNN model performed the best, with a macro average of 0.76 and a weighted average of 0.74. The CRNN model came second, with a macro average of 0.75 and a weighted average of 0.74. The Mel Spectrogram CNN model came last, with a macro average of 0.73 and a weighted average of 0.71.
Overall, all of the models performed really well, with the MFCC CNN model approaching state of the art performance. For such a complex task and such a simple model, this is a fantastic result. You can find the full jupyter notebook here.